Docs
- Introduction
- Overview
- Installation
- First Example
- Developer Guide
- Key Concepts
- Intent Matching
- Short-Term Memory
- Examples
- Calculator
- Time
- Light Switch
- Light Switch FR
- Light Switch RU
- Pizzeria
Key Concepts
NLPCraft is based on three main concepts:
- NCModel is a user-configured object responsible for input interpretation.
- NCPipeline is a part of the model that defines specifics of the step-by-step user input processing.
- NCModelClient is responsible for submitting user input to be processed by the model.
Here's the typical code structure when working with NLPCraft:
// Initialize data model including its pipeline.
val mdl = new CustomNlpModel()
// Creates client instance for given model.
val cli = new NCModelClient(mdl)
// Sends text request to model by user ID "user01".
val result = client.ask("Some user command", "user01")
Main Types
Here's the list of the main NLPCraft types:
| Type | Description |
|---|---|
| NCModel | Model is the main component in NLPCraft. User-define data model contains its NCModelConfig, input processing NCPipeline and life-cycle callbacks. NLPCraft employs model-as-a-code approach where entire data model is an implementation of just this interface. The instance of this interface is passed to NCModelClient class. Note that the model-as-a-code approach natively supports any software life cycle tools and frameworks like various build tools, CI/SCM tools, IDEs, etc. You don't need any additional tools to manage some aspects of your data models - your entire model and all of its components are part of your project's source code. Note that in most cases, one would use a convenient NCModelAdapter adapter to implement this interface. |
| NCToken | Tokens are produced by NCTokenParser that is part of the processing pipeline. |
| NCEntity | Entities are produced by NCEntityParser that is part of the processing pipeline. |
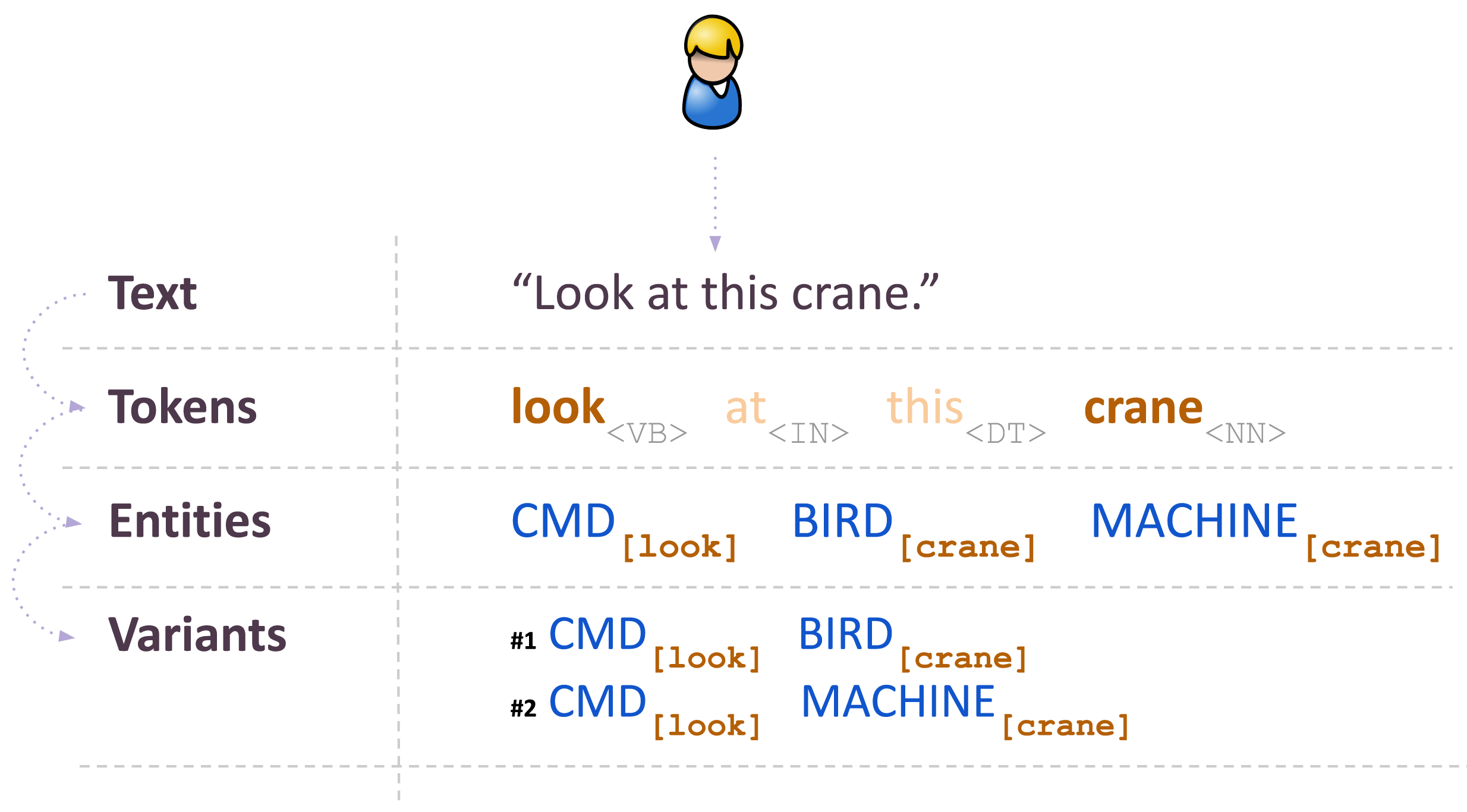
| NCVariant | Variant is a unique set of entities. In many cases, a token or a group of tokens can be recognized as more than one entity - resulting in multiple possible interpretations of the original sequence of tokens. Each such interpretation is defined as a parsing variant. For example, user input "Look at this crane." can be interpreted as two variants, one of them containing entity BIRD[crane] and another containing entity MACHINE[crane]. Set of variants ultimately serves as an input to intent matching. |
| NCPipeline | Pipeline is the main property of the model. A pipeline consists of an ordered sequence of pipeline components. User input starts at the first component of the pipeline as a simple text and exits the end of the pipeline as a one or more filtered and validated parsing variants. The output of the pipeline is further passed as an input to intent matching. |
| @NCIntent | @NCIntent annotation binds a declarative intent to its callback method on the model. The intent generally refers to the goal that the end-user had in mind when speaking or typing the input utterance. The intent has a declarative part or a template written in IDL - Intent Definition Language that strictly defines a particular form the user input. Intent is also bound to a callback method that will be executed when that intent, i.e. its template, is detected as the best match for a given input. |
Here's the illustration on how a user input text transforms into a set of parsing variants:
- On This Page
- Key Concepts
- Main Types
- Quick Links
- Examples
- Scaladoc
- Download
- Installation
- Support
-
JIRA -
Dev List -
Stack Overflow -
GitHub -
Gitter -
Twitter
